Understanding how machine learning models measure up to humans can help scientists make them more robust
(Image: Adapted from Jacob et al./Nature Communications)
A new study from the Centre for Neuroscience (CNS) at IISc explores how well deep neural networks compare to the human brain when it comes to visual perception.
Deep neural networks are machine learning systems inspired by the network of brain cells or neurons in the human brain, which can be trained to perform specific tasks. These networks have played a pivotal role in helping scientists understand how our brains perceive the things that we see.
Although deep networks have evolved significantly over the past decade, they are still nowhere close to performing as well as the human brain in perceiving visual cues. In a recent study, SP Arun, Associate Professor at CNS, and his team have compared various qualitative properties of these deep networks with those of the human brain.
Deep networks, although a good model for understanding how the human brain visualises objects, work differently from the latter. While complex computation is trivial for them, certain tasks that are relatively easy for humans can be difficult for these networks to complete. In the current study, published in Nature Communications, Arun and his team attempted to understand which visual tasks can be performed by these networks naturally by virtue of their architecture, and which require further training.
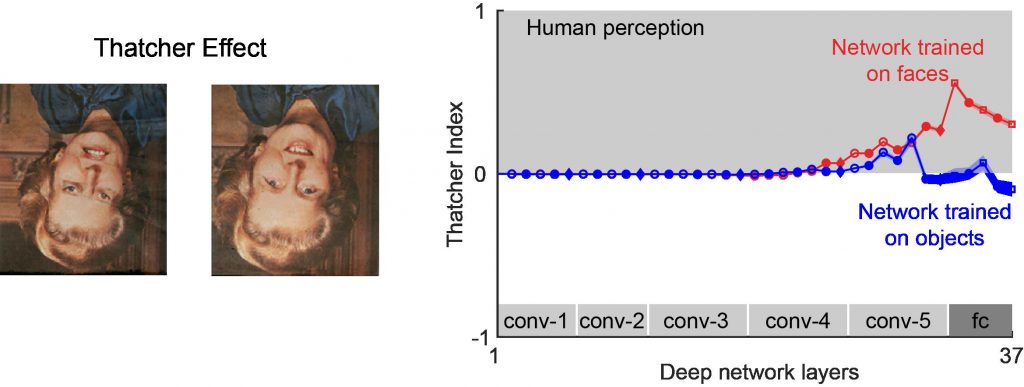
The team tested 13 different perceptual effects on the deep networks. An example is the Thatcher effect, a phenomenon where humans find it easier to recognise local feature changes in an upright image, but more challenging when the image is flipped upside-down. Deep networks trained to recognise upright faces showed a Thatcher effect when compared with networks trained to recognise objects. Another visual property of the human brain, called mirror confusion, was tested on these networks. To humans, mirror reflections along the vertical axis appear more similar than those along the horizontal axis. The researchers found that deep networks also show stronger mirror confusion for vertically-reflected images as compared to horizontally-reflected images.
Another feature peculiar to the human brain is that it first focuses on coarser details. This is known as the global advantage effect. For example, when we are shown an image of a tree, our brains would first see the tree as a whole before noticing the details of the leaves in it.
Similarly, when presented with an image of a face, humans first look at the face as a whole, and then focus on finer details like the eyes, nose, mouth and so on, explains Georgin Jacob, first author and PhD student at CNS. “Surprisingly, neural networks showed a local advantage,” he says. This means that unlike the brain, the networks focus on the finer details of an image first. Therefore, even though these neural networks and the human brain carry out the same object recognition tasks, the steps followed by the two are very different.
“Lots of studies have been showing similarities between deep networks and brains, but no one has really looked at systematic differences,” says Arun, who is the senior author of the study. Identifying these differences can push us closer to making these networks more brain-like.
Such analyses can also help researchers build more robust neural networks that not only perform better but are also immune to adversarial attacks that aim to derail them.





